




Описание
Продукт
Название
Nedra Data Platform
Обоснование продукта
Объединить разрозненные геологические и инженерные данные в единую экосистему для сквозной аналитики и управления ресурсами
Роль
Ведущий продуктовый дизайнер
Даты работ
2025 - настоящее время
Команда
Дизайнер (1)
Бэк (5)
Фронт (2)
Тестировщики (2)
Аналитики (4)
Руководитель проекта (1)
Владелец продукта (1)
Пользователи
Инженеры данных и геологи-эксперты с опытом работы с базами данных
Ключевая метрика
Целостность данных. Исключить риск накопления мусорных данных

Контекст и проблема
О фиче
Визуальный конструктор, где пользователи сами проектируют структуру хранения данных - будущие таблицы
Проблема
Сначала сделали акцент на хранении, а не на структуре. После импорта получили кучу несвязанных таблиц. Система превратилась в бесполезный цифровой архив
Решение
Перевернули процесс: сначала жёсткая модель данных, потом наполнение. Теперь данные всегда совместимы и легко связываются
Бизнес-цель
Сделать так, чтобы продукты платформы свободно обменивались данными на одном языке. Единая модель - фундамент для полной картины и качественных решений
Проблемы пользователей
Ручное сопоставление данных
Эксперты тратили часы на сопоставление разрозненных атрибутов из разных файлов
Моя задача
Гибкая продуктовая логика
Создать универсальный каркас системы способный адаптироваться под новые задачи бизнеса без дополнительных затрат на разработку

Процесс работы
Ключевая гипотеза
Гипотеза
Если дать пользователям инструмент для задания структуры данных до начала наполнения, то мы снизим количество ошибок, упростим согласование и обеспечим целостность данных при изменениях
Критерии успеха
Снижение количества ошибок
Сокращение времени на ручные проверки
Ускорение цикла согласования с экспертами
Исследования и архитектура
Анализ и ограничения
Сопоставила требования баз данных с нашими ресурсами. Сразу определила ограничения, чтобы отсечь нежизнеспособные идеи
Снижение рисков
Решила начать проектирование с самого нагруженного узла. Успешная архитектура сложного сценария гарантировала безопасное масштабирование всей системы
01
Страница модели
Проблема
Информационный шум и потеря фокуса при работе с массивными структурами
Решение
Внедрила паттерн прогрессивного раскрытия информации. Детальная панель адаптируется под выбранный объект, позволяя редактировать атрибуты без потери контекста общей структуры
Результат
Нулевой дизайн-долг. Новые параметры внедряются без затрат на редизайн и переобучение
Когда
Я работаю с масштабной моделью из сотен связанных объектов
Я хочу
Редактировать атрибуты конкретной сущности, видя общую структуру
Чтобы
Избежать ошибок из-за потери контекста и снизить когнитивную нагрузку
Решение
Трехблочный интерфейс с прогрессивным раскрытием деталей




02
MVP версионирование
Проблема
Ручная сверка версий занимала часы и приводила к потере данных при миграции
Решение
Осознанный отказ от сложной графики в пользу понятного списка изменений. Это позволило выпустить критичную функцию в два раза быстрее
Результат
Пользователи без знания кода получили прозрачный инструмент контроля, а бизнес сэкономил ресурсы на разработке
01
Создание новой
версии модели
02
Изменения
в новой версии
03
Проверка
и согласование
04
Преобразование
данных
03
Статусная модель
Проблема
После реализации флоу пользователи теряли контекст прогресса при работе с моделями данных
Решение
Полностью переработала статусы модели. Ушла от трансляции системных состояний к продуктовой логике: переработала 9 разрозненных статусов в 3 интуитивных бизнес-этапа
Результат
Интерфейс стал самодостаточным. Команда и новички считывают логику процесса моментально, не прибегая к спецификациям
Когда
Я управляю жизненным циклом модели данных
Я хочу
Видеть понятный и прозрачный бизнес-процесс
Чтобы
Моментально считывать контекст прогресса
Решение
Консолидация системных статусов в интуитивные этапы

04
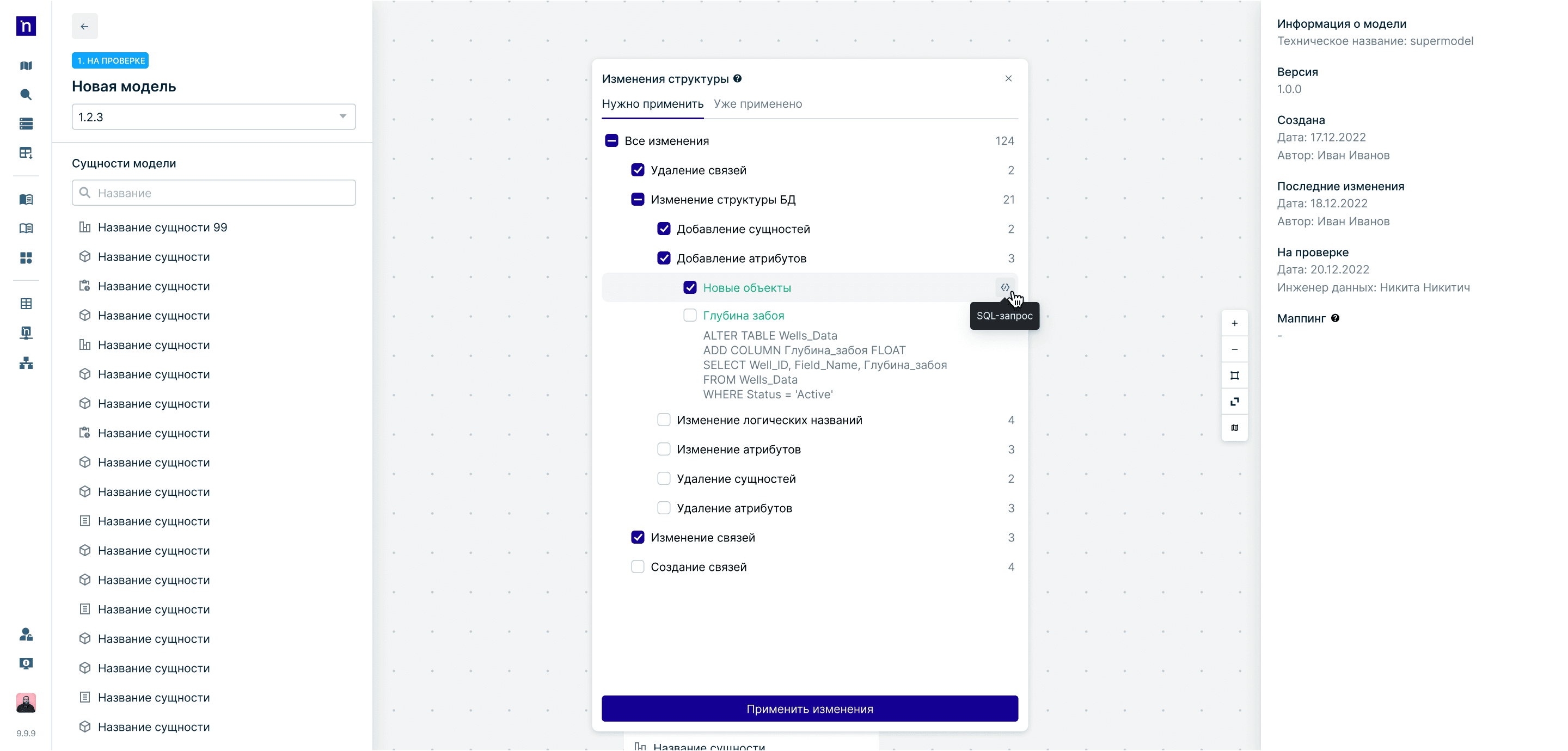
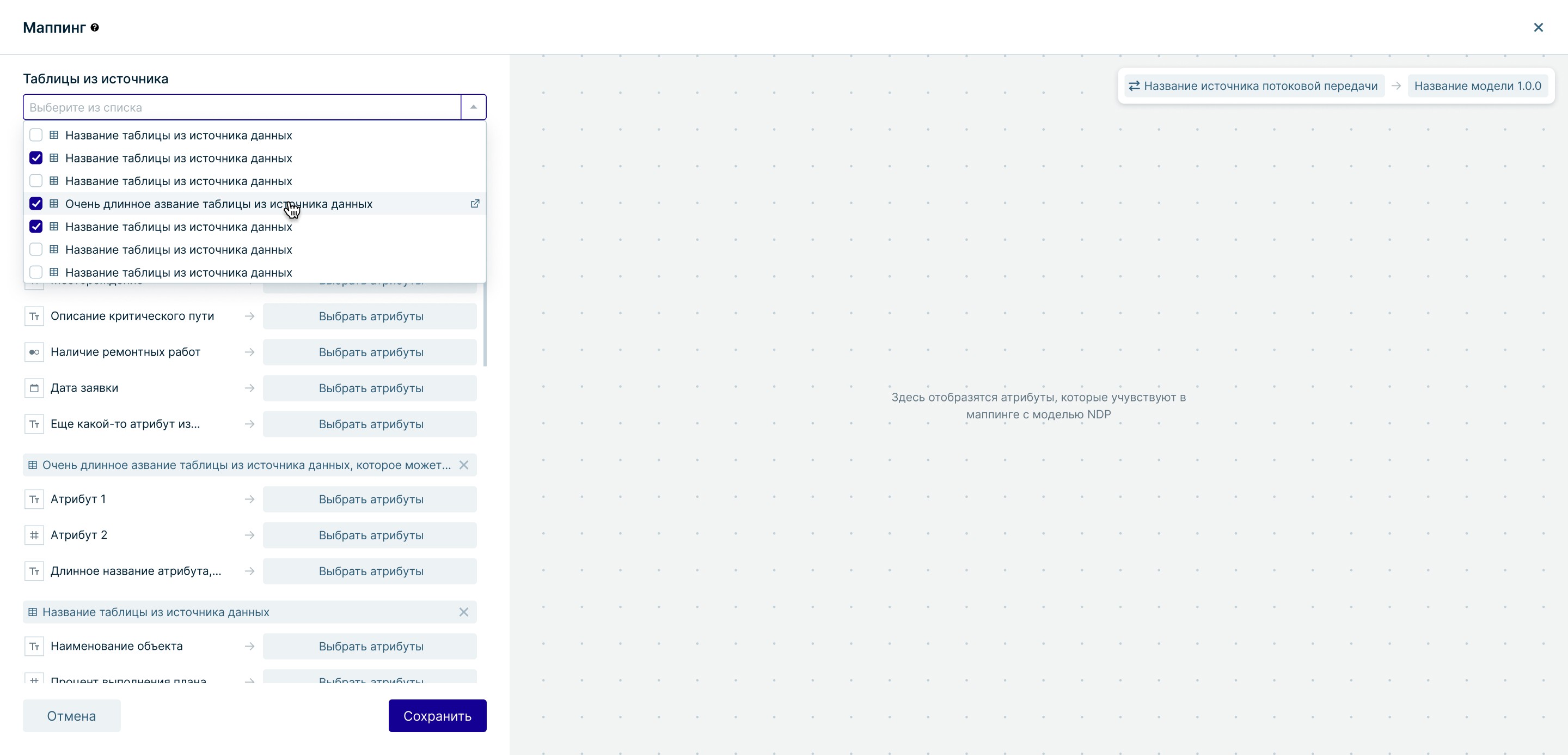
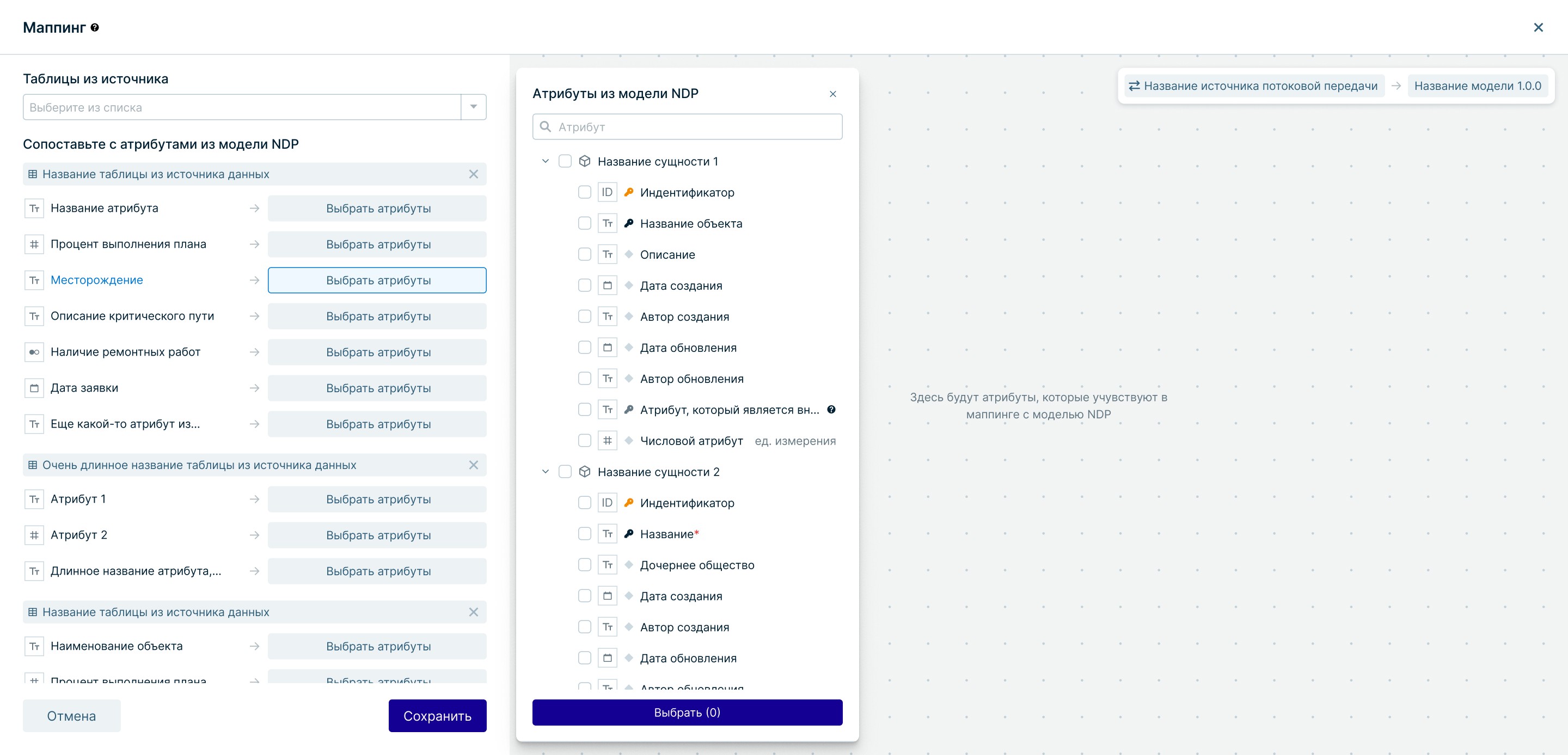
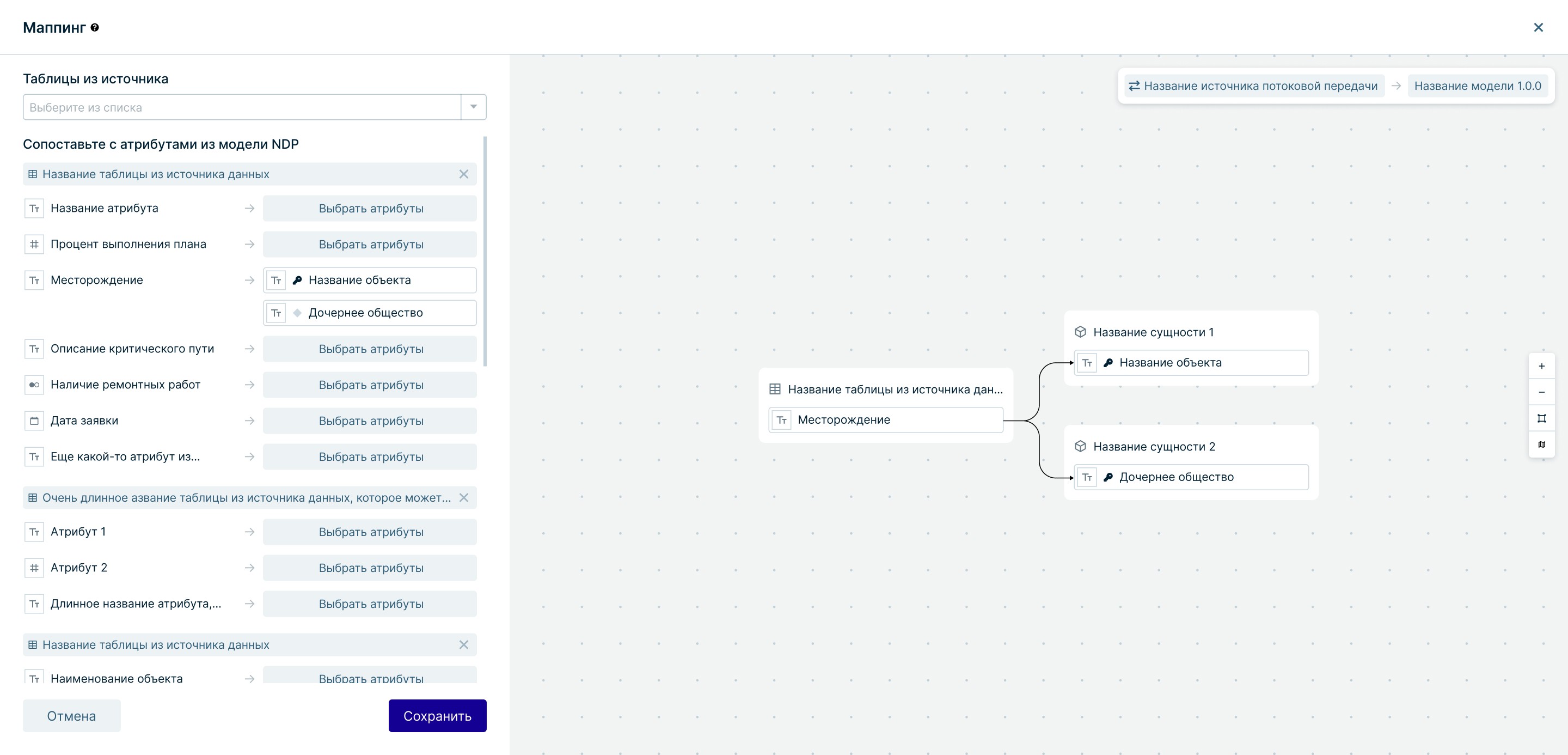
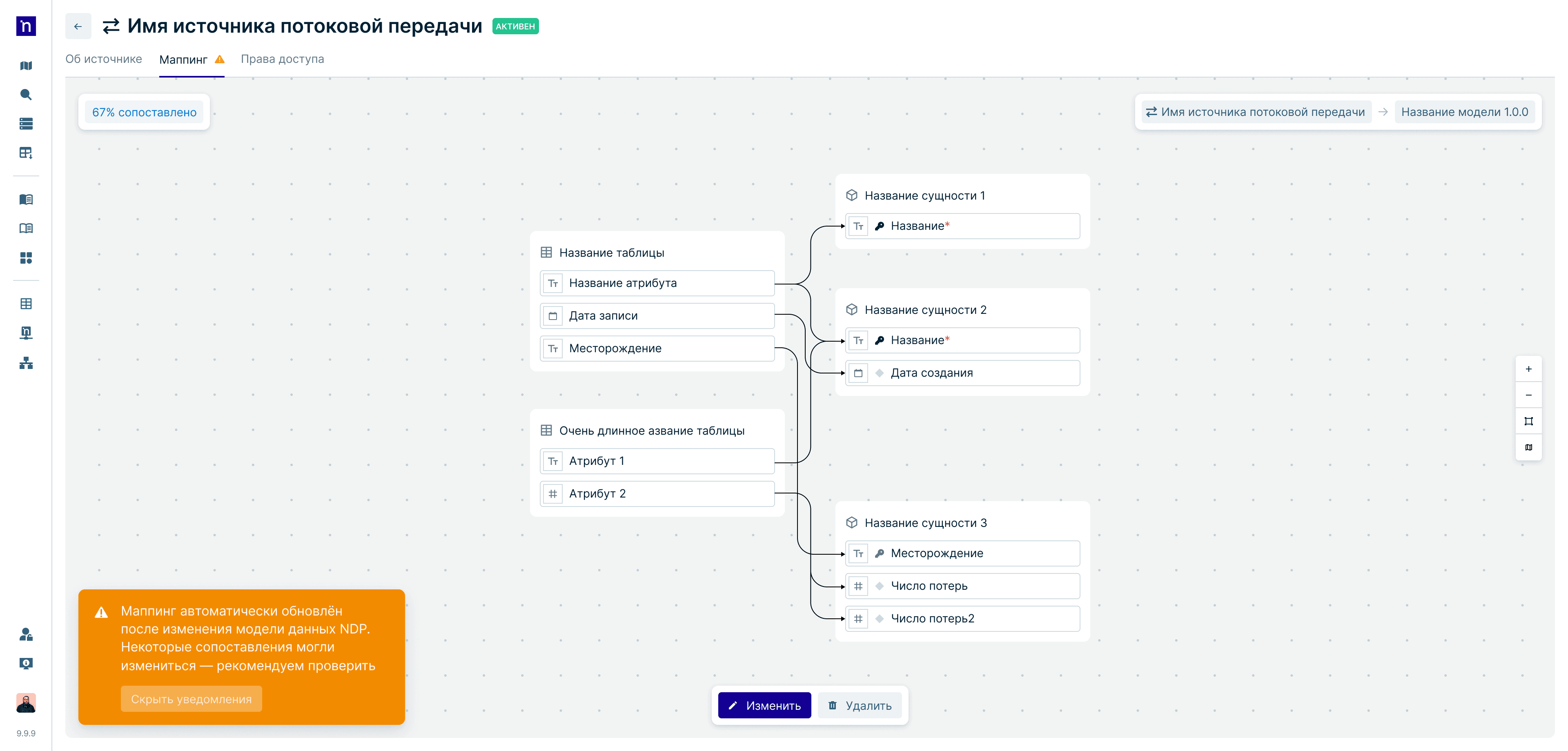
Маппинг данных
Проблема
Разнородные структуры баз создавали хаос и требовали точечной настройки для любых операций передачи данных
Решение
Инструмент гибкого сопоставления логических моделей с ядром системы. Добавила метрику покрытия и индикацию устаревших связей
Результат
Система защищена от информационного мусора. Процессы трансформации масштабируются на все подключенные источники автоматически благодаря единому стандарту
Когда
Я подключаю новый источник данных к платформе
Я хочу
Связать структуру источника с главной моделью
Чтобы
Подготовить фундамент для переноса данных
Решение
Независимый инструмент маппинга с аналитикой
Системность
и масштабируемость
Переиспользование паттернов
Заложила гибкую архитектуру на базе проверенных решений. Это ускорило разработку и упростило масштабирование системы
Взаимодействие с командой
Синхронизация и фокус
Валидировала логику с инженерами до создания макетов и помогла приоритизировать задачи при нестабильных требованиях. Это исключило ошибки на старте и обеспечило релиз в срок без переработок
Результаты и рефликсия
Бизнес-результаты
Успешная работа над ошибками
Модель данных стала основой миграции. Добавили маппинг и валидацию - теперь даже старые данные легко встраиваются в новую структуру
Подтверждение главной гипотезы
Пользователи перестали создавать «свалку» таблиц и перешли к осознанному хранению данных. Качество данных выросло: в систему попадает только проверенная информация
Self-Service для экспертов
Геологи и аналитики теперь сами проектируют и меняют структуру данных. Цикл внесения изменений сократился с недель до часов
Уменьшилось кол-во вопросов
На демо и обучении новых сотрудников больше не нужно ничего объяснять - интерфейс говорит сам за себя
Ретроспектива
Сплоченность как ключ к результатам
Теперь всегда ставлю параллельную работу на первое место: регулярные обсуждения, общие обновления и полная прозрачность. Это помогло оставаться на одной волне, быстро адаптироваться и превратить неопределённость в преимущество
От сложного к простому
Начинаю с самых сложных сценариев. Если дизайн выдерживает максимальную нагрузку — простые случаи собираются сами, без лишних рисков и переделок